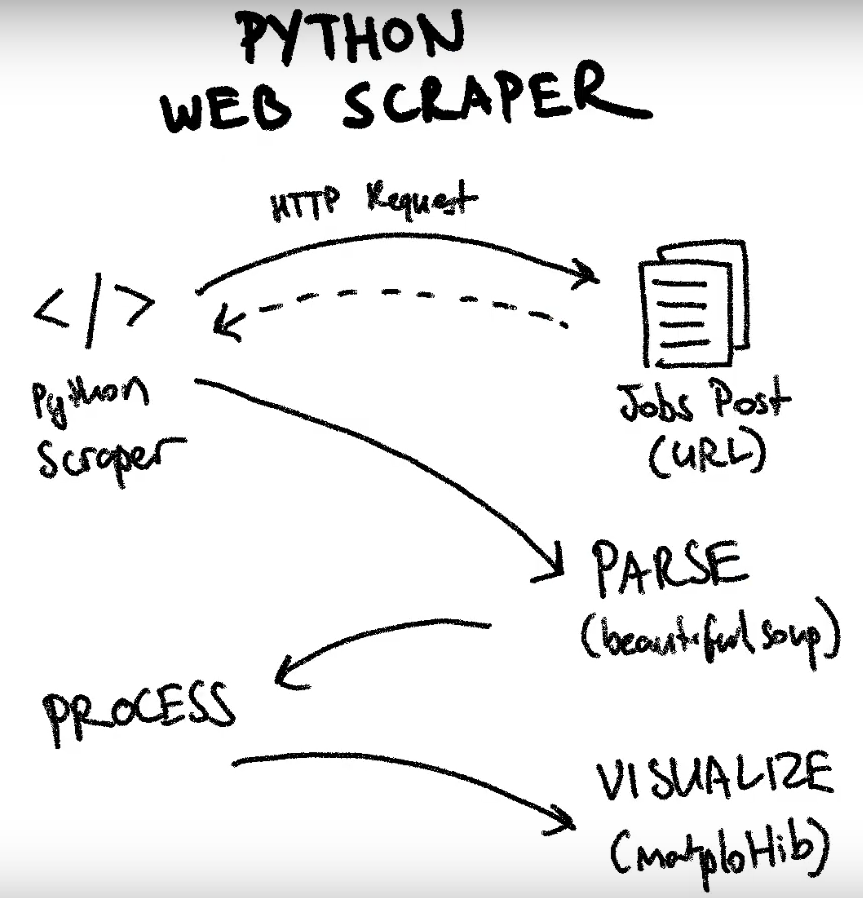
Python Web Scraping Tutorial
- Lab Objectives
- Make an HTTP request
- Parse the HTTP response with “Beautifulsoup”
- Extract individual comments
- Clean up the response text
- Process the scraped content for useful data
- Visualizing the data with “matplotlib”
- What Next?
- Mini Project to do in pairs
Lab Objectives
- Create a Pyhton script to scrape job postings from a forum post.
- Analyse the data to see how popular different technologies are.
> Web Scraping Ethics
- Be mindful about how you scrape!
- Don’t overdo it. Request data at a reasonable rate. Respect the owners of the data.
Make an HTTP request
- Create an empty python file
scraper.pycontaining the following code:
def main():
print('Hello world!')
if __name__ == "__main__":
main()- Create a virtual environment:
python -m venv .venv- Activate the virtual environment:
.\.venv\Scripts\activate- lunch the program:
python scraper.py- We want to scrape this web site: https://news.ycombinator.com (Hacker News), every month there is post in Hacker News called
Ask HN: Who is hiring? - This is the Hacker News - Ask HN: Who is hiring? (February 2025) link : https://news.ycombinator.com/item?id=42919502
- In the main function, add an url variable:
def main():
url = "https://news.ycombinator.com/item?id=42919502"
print(f"Scraping: {url}")
if __name__ == "__main__":
main()- Let’s retrieve the contents of this link, we have to install the
requestslibrary and import it:
pip install requestsRequests is an elegant and simple HTTP library for Python, built for human beings (docs)
import requests
def main():
url = "https://news.ycombinator.com/item?id=42919502"
response = requests.get(url)
print(f"Scraping: {url}")
print(response)
if __name__ == "__main__":
main()- Execute the program and you will get this result:
Scraping: https://news.ycombinator.com/item?id=42919502
<Response [200]>- You can also show the response content and you will get all the data:
print(response.content)Parse the HTTP response with “Beautifulsoup”
- With response.content we get all the data, we have to parse data and make it more clean and exploitable.
- For that we will use an other library called
beautifulsoup:
pip install beautifulsoup4Beautiful Soup is a Python library for pulling data out of HTML and XML files (docs).
To scrape the web site, we have to know the web page structure, for that inspect the web page in the browser to find out if there is any kind of class or id we can use to identify a particular job post.
- To use Beautifulsoup, give it the response content and a parser (in this case it will be a html parser):
import requests
from bs4 import BeautifulSoup
def main():
url = "https://news.ycombinator.com/item?id=42919502"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# find all elements with class="comment"
elements = soup.find_all(class_="comment")
# Show the number of elementd found
print(f"Elements: {len(elements)}")
if __name__ == "__main__":
main()Extract individual comments
- After analysing the web site to scrape, you will find that what interest us is the elements with indentation 0 and their next element with content info:
import requests
from bs4 import BeautifulSoup
def main():
url = "https://news.ycombinator.com/item?id=42919502"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# find all elements with class="ind" and indent level = 0
elements = soup.find_all(class_="ind" , indent=0)
# for each of this elements, find the next element
comments = [e.find_next(class_="comment") for e in elements]
# Show the number of comments found
print(f"Comments: {len(comments)}")
if __name__ == "__main__":
main()- Execute the new code
- Replace:
print(f"Comments: {len(comments)}")with
# show each comment (job post)
for comment in comments:
print(comment)Clean up the response text
- After executing the last modification, you will notice that still we have a lot of html tags that we want to get rid of that.
- We can use comment.get_text():
import requests
from bs4 import BeautifulSoup
def main():
url = "https://news.ycombinator.com/item?id=42919502"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# find all elements with class="ind" and indent level = 0
elements = soup.find_all(class_="ind" , indent=0)
# for each of this elements, find the next element
comments = [e.find_next(class_="comment") for e in elements]
# show each comment (job post)
for comment in comments:
comment_text = comment.get_text()
print(comment_text)
if __name__ == "__main__":
main()- Execute the file again and it will look better!
Process the scraped content for useful data
- We want to find out how often each technology is mentioned. We will limit to programming languages. We will look in each of this comments and see how many times a language like Python for example is mentioned or Javascript, Java, etc.
- We will create a map of different languages we are interested in and then for each of these comments we will scan the words for occurrences of that language and count them. Also, we will count each keyword once for each unique post because we don’t want a post that mentions for example Javascript several times to count as three different things! We will only count once the post that mention Javascript for example.
- Create the map of languages:
import requests
from bs4 import BeautifulSoup
def main():
url = "https://news.ycombinator.com/item?id=42919502"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# find all elements with class="ind" and indent level = 0
elements = soup.find_all(class_="ind" , indent=0)
# for each of this elements, find the next element
comments = [e.find_next(class_="comment") for e in elements]
# Map of technologies keyword to search for
# and the occurence initialized at 0
keywords = {"python": 0, "javascript": 0, "typescript": 0, "go": 0, "c#": 0, "java": 0, "rust": 0 }
# show each comment (job post)
for comment in comments:
# get the comment text and lower case it
comment_text = comment.get_text().lower()
# split comment by space which create an array of words
words = comment_text.split(" ")
print(words)
if __name__ == "__main__":
main()- Execute the code. You will notice that in the array some of words contains punctuations, and also some words that repeating so we only want to count them once.
- We definitely have to clean this up, we can do that by using the
strip()function to strip the words. We do that for each word. - After the split instruction, add:
# Use the string strip function
# and place all the caracters we want to strip away
words = [w.strip(".,/:;!@") for w in words]- Execute the code.
- Convert the list of words to a
setto make the words unique and get rid of duplicate words, for that just replace the previous code with:
# Use the string strip function
# and place all the caracters we want to strip away
# Use a set to have unique words
words = {w.strip(".,/:;!@") for w in words}- Now that we have processed and cleaned up the scraped data, we can count our keywords inside the set. Replace the
print(words)instruction with the following code:
# search for k in keywords, this give you the dictionory key
# if the key is in the words set, we add 1 to the keywords score
for k in keywords:
if k in words:
keywords[k] += 1- Just after the
for comment in comments:loop, print out the keywords:
print(keywords)- Execute the code.
Visualizing the data with “matplotlib”
- Now we will try to visualize the results in a graph, for that we will install
matplotlib(most popular plotting library in python - (docs) dependency:
pip install matplotlib- To use matplotlib library, we have to import it:
import matplotlib.pyplot as plt- After
print(keywords)instruction, add the following code:
# plot a bar graph
plt.bar(keywords.keys(), keywords.values())
# Add labels
plt.xlabel("Language")
plt.ylabel("# of Mentions")
plt.show()- Execute the code.
- Generate
requirements.txt:
pip freeze > requirements.txtWhat Next?
- Adapt the scraper to different websites.
- Turn the scraper into a serverless API.
- Use Selenium for complex browser interaction.
- Store the Scraped Data in CSV file or database.
- Create a Web Board Interface
Mini Project to do in pairs
Here are 4 interesting web scraping ideas, choose one of these:
- Product Price Tracker:
- Scrape product prices from e-commerce websites to monitor price changes.
- Send notifications when prices drop or hit a target price.
- Useful for deal-hunters or businesses analyzing market trends.
Web sites samples:
- News Aggregator:
- Collect news articles from multiple sources and compile them into a single feed.
- Filter articles by keywords or topics of interest.
- Summarize articles to get the gist quickly.
Web sites samples:
- Job Listings Scraper:
- Gather job listings from various job boards.
- Filter jobs by location, industry, or company.
- Useful for job seekers looking for specific opportunities.
Web sites samples:
- Social Media Sentiment Analysis:
- Scrape social media platforms (e.g., Twitter) for posts mentioning a particular topic or hashtag.
- Perform sentiment analysis on the collected data to gauge public opinion.
- Useful for businesses or individuals monitoring brand reputation or trends.
Web sites samples:
By Wahid Hamdi